 Backlog Migration for Redmine
Backlog Migration for Redmine
並行処理プログラミングでお困りの方いないでしょうか?
作ったが複雑になった、何が起こるか心配、なぜか不安定など色々あると思います。
私も並行処理プログラミングは難しいと思っていました。今回、並行処理フレームワークであるAkkaを使用し、RedmineからBacklogへの移行ツールを作ってみたので紹介します。
移行ツールを作った理由
プロジェクト管理ツールには、プロジェクトに関する作業や知識など貴重な情報が大量に蓄積されます。オープンソースのプロジェクト管理ソフトウェアとして多く使われているのはRedmineです。
RedmineからBacklogへ移行する時、データを移行できないとせっかくためた貴重な情報を生かすことができません。しかし、手作業で移行する場合は移行自体に時間がかかり、結局移行できない場合がほとんどです。そのために移行ツールをご用意しました。
移行ツールの概要〜並行処理で同時にインポートする
移行ツールは次の手順でプロジェクトを移行します。
次の図のようになります。
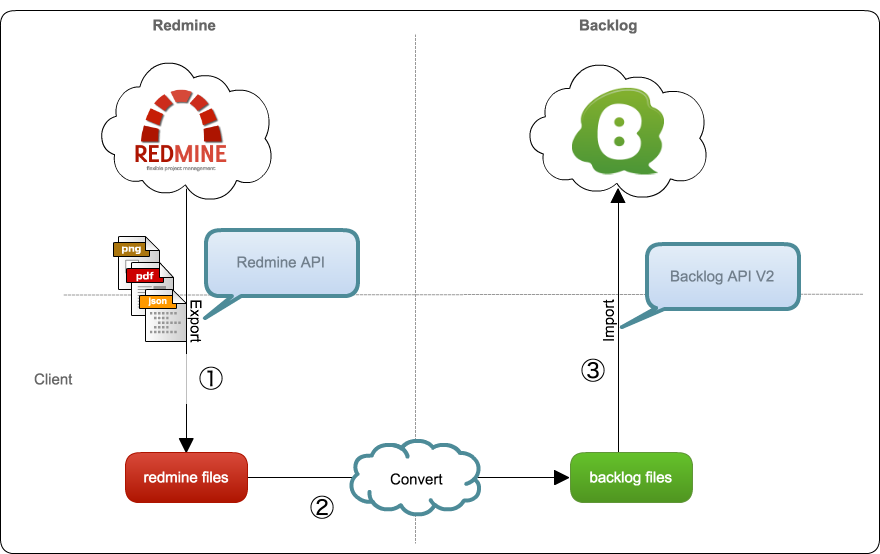 概要
概要
インポート処理は次の図のように、複数プロジェクトを並行して処理します。また、登録量が多い課題とWikiに関しても並行して登録します。
 インポートフロー
インポートフロー
Akkaとは?
Akkaはアクターモデルを使った並行処理ができるフレームワークです。
JavaやScalaで使うことができます。Play FrameworkというJavaやScalaで人気のあるwebアプリケーションフレームワークでも内部的にAkkaが使用されています。
また、アクターモデルとは簡単に説明すると、アクターと呼ばれるオブジェクトが、内部のメールボックスというメッセージを溜めておく箱のような仕組みを使用し、メッセージのやり取りを非同期に行うことができる並行処理のシステムです。
 アクターモデル
アクターモデル
なぜAkkaを使った?
なぜAkkaを使ったのかというと、並行処理にすることでマイグレーションにかかる時間をできるだけ短縮したかったためです。(個人的にAkkaを使ってみたかったっていうのは内緒です。)
Akkaを使うメリット
スレッド割り当ての制御ができる
並行処理プログラミングでアプリを組んでいると、次のような場合に簡単にチューニングできます。
- 「いいサーバーに変えたのでもっとスレッド数を増やしたい!」
- 「思ったよりパフォーマンスでないからスレッドを減らしたい」
AkkaにはDispatcherという並行処理の実行仕方を制御できる仕組みがあります。
デフォルトではfork-join-executorという設定になります。
parallelism-min、parallelism-factor、parallelism-maxの値を設定して制御します。
| parallelism-factor | 認識されたプロセッサの数 * この設定値が、スレッド数として使用されます。 |
| parallelism-min | スレッドの最小数。parallelism-factorがこの値より小さい場合、この値が使用されます。 |
| parallelism-max | スレッドの最大数。parallelism-factorがこの値より大きい場合、この値が使用されます。 |
application.confで次のように設定することができます。
my-dispatcher {
# Configuration for the fork join pool
fork-join-executor {
# Min number of threads to cap factor-based parallelism number to
parallelism-min = 2
# Parallelism (threads) ... ceil(available processors * factor)
parallelism-factor = 2.0
# Max number of threads to cap factor-based parallelism number to
parallelism-max = 10
}
}
Play Frameworkでも設定できるのでお試しください!
耐障害性
「親アクターが子アクターをたくさん作った場合に、子アクターの1つで障害が発生した場合どうなるんだろう?」と思わないでしょうか。「子アクターで致命的な障害が発生した場合はアプリケーション全体を落としたい」と考えるかもしれません。
Akkaでは監視戦略(Supervisor Strategy)というもので障害発生時にどのような処理をするのか制御できます。
監視者(Supervisor)が監視対象である子アクターを監視することで制御します。
One-For-One StrategyとAll-For-One Strategyの2種類の戦略があります。
-
One-For-One Strategy:監視対象の子アクターのいずれかで障害が発生した場合に、対象のアクターにDirectiveで設定した処理をさせます。
-
All-For-One Strategy:監視対象の子アクターのいずれかで障害が発生した場合に、すべてのアクターにDirectiveで設定した処理をさせます。
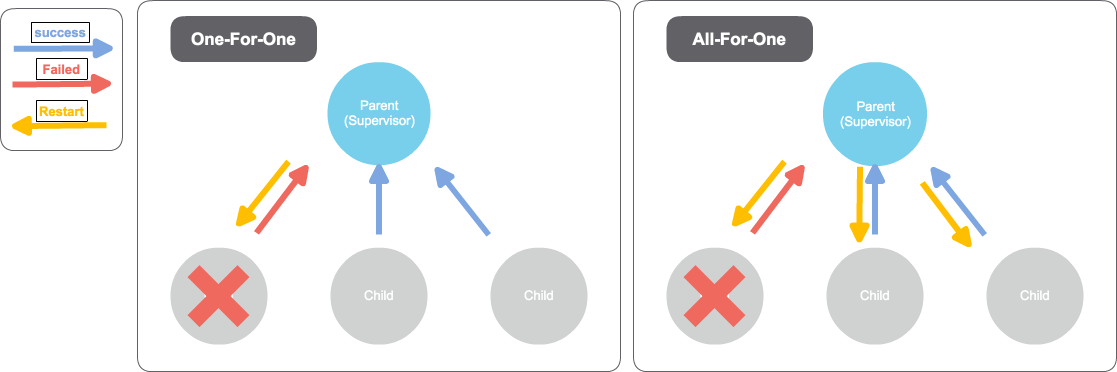 監視戦略
監視戦略
Directiveには次の設定ができます。
- Resume:アクターをリスタートします。
- Restart:アクターを再作成し、アクターをリスタートします。
- Stop:アクターを止めます。
- Escalate:親アクターに障害処理をエスカレートします。
次のようにアクタークラス内に実装します。エラーによってDirectiveを設定できるのは便利ですね。
maxNrOfRetriesはリスタートを試みる回数、withinTimeRangeはリスタートする時間の間隔になります。
override val supervisorStrategy =
OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {
case _: ArithmeticException => Resume
case _: NullPointerException => Restart
case _: IllegalArgumentException => Stop
case _: Exception => Escalate
}
結果は目に見えてパフォーマンスアップ
処理速度という面では、課題の数が30件ほどのプロジェクト3つを移行する場合、Akkaを1スレッドで実行すると処理時間は1分30秒、Akkaを4スレッドで実行すると処理時間は39秒と目に見えて効率化することができました。さらに大きなプロジェクトになってくると効果をより発揮してくると思います。
Akkaを使ってみて、Javaのスレッドしか使ったことなかった私にとっては、次の点が非常にいいと感じました。
- 実装するのが簡単
- 複雑にならない安全なソースコード
- 耐障害性を持ち安心できる
並行処理に関する部分については、安心して実装できほとんど時間もかかりませんでした。
もう普通のスレッドプログラミングには戻れません!!
最後に
実はScala未経験でありながら、今回のプロジェクトはScalaで実装しました。
Scalaは基本的にイミュータブルで実装する必要があるため、これまでミュータブルで実装していた部分に関して、どのように実装するんだろう?と悩むことも多かったです。しかし、イミュータブルで実装していくと、スパゲッティコードになりにくいと感じました。
ただでさえ複雑になりやすい並行処理プログラミングでは、ScalaとAkkaの組み合わせはオススメです!!
まだ、ベータ版ですが移行ツールのソースはGitHubに公開しています。
RedmineからBacklogへの移行する必要がある方はおためしください。
https://github.com/nulab/BacklogMigration-Redmine
—
ヌーラボではScalaを書きたい!というエンジニアを募集しています(もちろんそうでない方も募集しています)。