このエントリは前後編に分かれています。前編は主に運用フローやそこでの工夫点、後編は実際の運用から得た知見や今後の課題といった内容です。
最近はインフラ運用・DevOPS関連のトピックとして目にしないことはないくらい、「イミュータブルインフラストラクチャー」について様々な議論がなされています。私たちも昨年、継続的デリバリという文脈で、
@IT の連載にてその基本的な考え方について紹介させていただきました。
さて、今年の二月にローンチをしたばかりのヌーラボのシングルサインオンサービス「
ヌーラボアカウント」では、イミュータブルインフラストラクチャの一歩手前として、特定の変更を加える場合のみ、ごっそり環境ごと入れ替えるというやり方にてその運用をスタートしました。
そこに至るまでの背景や、具体的に工夫したこと、そして二ヶ月ほど運用して見えてきた悩みと今後の展望について、前後編に分けてご紹介します。まず前編はインフラ運用における課題と、それを解決すべく構築したフローとそこにおける工夫点についてです。尚、ここであげるヌーラボサービスは全て AWS 上で稼働しており、それを設計の前提としています。
それまでのインフラ運用における課題
1. 構成管理ツールの設定の信頼性の低下
私たちは昨年の 8 月
Typetalk のプレビューローンチにあわせてサーバ構成管理ツールとして
Ansible の導入を開始し、その他のサービスへの展開を順次進めています。Ansible を利用することで、それまで暗黙知だったサーバの設定やセットアップ手順などが形式知化していき、インフラ設定に関するナレッジ共有にも多いに役にたちました。
一方でその Ansible の設定そのものへの信頼が度々損なわれることがありました。というのも一旦本番で稼働し出すと、あるロール (例えばウェブサーバ) に対する playbook を稼働サーバに全適用することは稀です。そのかわりに、例えばnginx の設定ファイルを更新するといった、部分的な適用のみを行います。これは主に実行時間を短縮するためで、Ansible だと以下のようにタグにて実現できます。
$ ansible-playbook -i production web.yml --tags=nginx_conf_update
Ansible のタグは便利な反面、例えば追加されたタスクはタグ指定では問題なく動作しても、定義の順序に誤りがあって全体を通して実行すると動かなくなることがあります。また、Ansible は活発に開発がなされており、一部の設定が Ansible のバージョンアップにより動かなくなってしまうといった事も発生しました。こういった経験から Ansible の設定をグリーンに保つために、定期的にゼロベースで Ansible を実行してそれが常に機能することを確認するという、いわば CI 的な処理を行う必要を感じていました。
2. 手動で実施されるミドルウェアのバージョンアップ
例えば nginx のバージョンをあげたい、モジュールを追加で組み込みたい、といった時に、「インストールされている状態」「古いバージョンがインストールされていない状態」を各々定義し、実行することは構成管理ツールでできます。ただし、稼働しているサーバに対して、サービスに影響を与えずに変更するのは簡単ではありませんし、場合によっては設定をシンプルに保つのが難しくなる事もあるでしょう。
こういった場合、手動でバージョンアップを行い、その後 Ansible の設定を更新していました。結果としてこういった作業手順は暗黙知となりがちですし、Ansible の設定を更新し忘れると、サーバの状態と設定が乖離する結果にもつながります。
順序としては構成管理ツールで管理されたものが稼働環境に入っていくことが望ましいですし、また、こういったバージョンアップはセキュリティ問題への対処として行う事が多いので、極力迅速に心理的な負荷も小さく行いたいと考えていました。そういった点において、ブルー・グリーンデプロイメント的に環境毎入れ替えるというアプローチを取る事が望ましく思えました。
3. 職人の秘伝のタレ化しやすいインフラ運用体制
先日の
NUCON の発表でもありましたが、昨年までは少数のエンジニアがアプリ開発と兼任でインフラの運用を行っていました。ただ Typetalk とヌーラボアカウントのローンチが正式に決まり、その体制では安定的なサービス運用を行うことは難しいと考え、各サービスのアプリ開発担当がインフラ運用を兼任する形に体制を変更することになりました。
ヌーラボではアプリ開発担当のエンジニアも、比較的 UNIX 環境に慣れていますが、やはりサービスの運用となると不安に感じる部分もあります。そこで障害対応やインスタンスのメンテナンスなどの理由により、まっさらのインスタンスを立ち上げるという作業は、極力ツールによる自動化を促進し、職人の秘伝のタレが入り込みにくいような運用プロセスを設計する事がスムーズな体制変更の助けになると考えました。
こういった背景から、ヌーラボアカウントでは結果的にイミュータブルインフラストラクチャーの一歩手前、特定状況でのみ環境を入れ替えるというプロセスでその運用を開始するに至りました。
ヌーラボアカウントでの現在の運用
まず環境を全て入れ替える条件としているのは、
- ミドルウェア、実行環境のバージョンアップ
- インスタンスの追加
です。前者は上でも述べた nginx や JDK のバージョンアップといったものが挙げられます。後者は、追加されたインスタンスと既存のインスタンスに差異が出ないようにするためです。言い換えると、通常のアプリ更新や nginx の設定変更などでは環境の入れ替えは行わず、Fabric や Ansible にて稼働環境に変更を加えています。
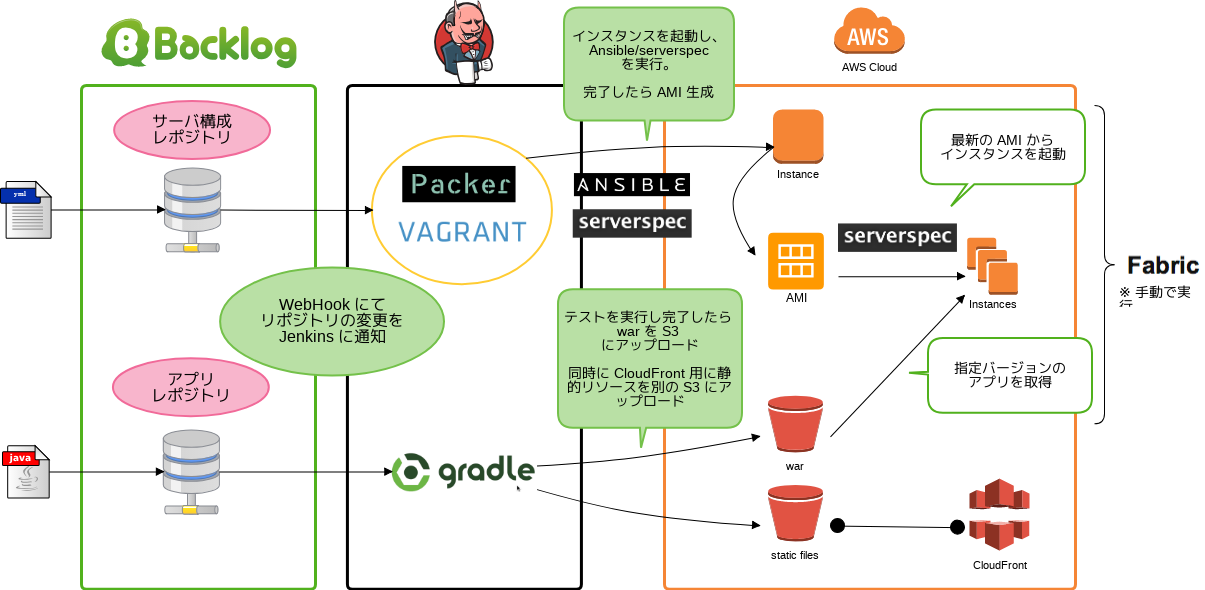
この運用の全体のワークフローは以下のようになります。
まず、ゼロベースで Ansible の構成を走らせる処理を Jenkins により行っています。トリガーとなるのは Ansible の設定に変更が加わった時と、定期実行の二つです。これは、設定に変更はなくてもベースとなる Amazon Linux には随時セキュリティアップデートがかかるため、最新の環境で構成が走る事を確認するためです。実際、ここで実行される Ansible のタスクには以下のようなインストールされているパッケージを最新版にするものが含まれています。
- name: yum update yum: name=* state=latest
構成管理的にいえば、ある時点での環境を再構成出来ることを重視しますが、私たちはサービスを最新の環境で稼働出来ることのほうにより重きを置いています。つい先日も Amazon Linux のアップデートが原因でビルドが通らなくなる事が発生しました。こういった最新環境への追従は日常的なプロセスの中に組み込まれておく方が好ましいと考えています。
Jenkins のジョブが成功すると AMI として保存しますが、この時に Created というタグに作成日のタイムスタンプをエポックからの経過秒数として保存しています。現状の EC2 の API では、AMI の取得結果にはその AMI の作成日が含まれていないため(
参照) 、この情報を付与することで、後にインスタンスを起動する際に同じタグを持つ複数の AMI の中からどの AMI が最新かをタグの値をソートするだけで簡単に見つけることが出来ます。
AMI 作成に
Packer を用いている場合は builder 要素に以下のような tags 要素を追加します。
"tags": { "Name": "base", "Created": "{{timestamp}}", }
Vagrant ami plugin を使って生成する場合は、以下のように引数で渡します
vagrant create-ami --name "base" --tags Name=base,Created=$(date +%s)
そして、AMI の起動時に最新のものを見つけるための boto を用いた Python のコードは以下のようになります。
def find_latest_ami(name):
"""
指定された名前の AMI で最新のものを返す
"""
ec2 = boto.connect_ec2(region=find_region())
images = ec2.get_all_images(owners=['self'], filters={
'tag:Name': name,
'tag:Created': '*'
})
if len(images) == 0:
return None
images.sort(key=lambda img: int(img.tags['Created']), reverse=True)
return images[0]
私たちはインスタンスの起動は Fabric にて行うようにしており、入れ替え時には上記のように自動的に最新の AMI を探してきて起動するようにしています。
一方アプリケーションがリリースされるまでのフローは以下のようになっています。
- リリースタグを打つ
- WebHook で Jenkins ジョブがテスト実行
- テストが成功したら war と静的ファイル (CloudFront 用) を S3 にアップロード
- S3 からファイルをアプリサーバに展開
- 一台ずつアプリケーションサーバのアプリケーションを入れ替え
基本的にタグを打った後のテストと S3 へのアップロードは Jenkins が行い、S3 からファイルを取得してローリングリリースを実施するのは Fabric により任意のタイミングに手動で実行しています。
ここから見ての通り、インフラ側もアプリケーション側もどちらも Git リポジトリへの push をフックとして各種の処理を走らせ、AMI や war といった成果物を保存するという流れになります。そしてそれらの成果物を組み合わせて本番に反映しています。
サービス設計上の工夫点
インスタンス増減を前提とした AWS 設計
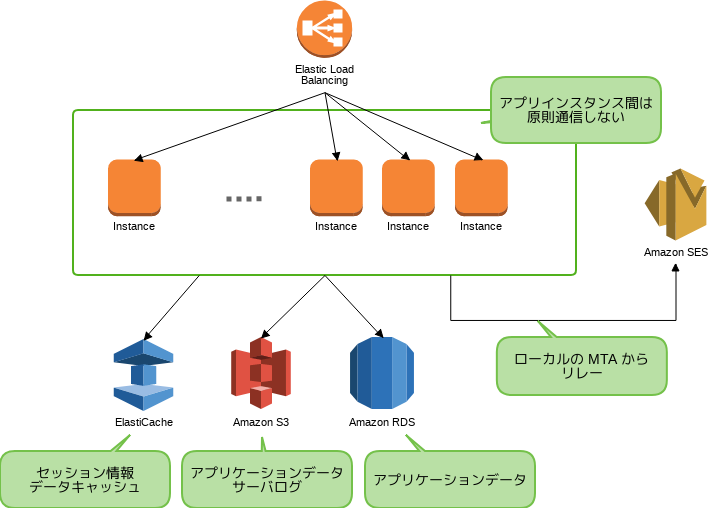
アプリケーションに関わる AWS 設計を抜き出すと以下のようになります。
この設計においては以下の三点を考慮しました。
- プライベート IP を固定しない
- 自前管理のインスタンス間では極力通信しない
- データストアを自分で管理しない
まず VPC を利用しているので内部ホスト名の解決は IP を固定したほうが運用上楽な点もままありますが、インスタンスの入れ替え時の考慮事項を増やすことになるので、あえて動的なままで運用しています。入れ替え時には EC2 のタグをベースに /etc/hosts を自動更新するスクリプトを利用しています。
次にインスタンス間で通信を行う場合、内部の IP の変更への考慮をする必要が少なからず出てきます。例えば、セッション情報の保持のために Tomcat の
memcached-session-manager を使っていますが、このライブラリはホスト名を解決した IP をキャッシュしてしまうため、アプリケーションサーバに同居して memcached を動かすと、インスタンスの増減の度にクラスタ全体を再起動しないといけなくなります。また、MTA についても、他のサービスでは柔軟な配信の調整が出来る点などから自前で MTA を運用していますが、その為にはメールを送信する外向けの MTA には EIP を付与し、逆引き申請をしないといけないという、柔軟なホストの増減を阻害する要因を増やすことにもなります。ヌーラボアカウントではそれらをさけるために ElastiCache や SES を採用しました。
データストアに関しては耐障害性や運用の容易さ、開発チームのデータストアに関するナレッジなどから RDS を利用しています。ヌーラボアカウントはシングルサインオンサービスなため、停止が与えるインパクトは甚大な一方、冒頭にも述べたように運用チームの人数は限られているため、当初から RDS の採用を前提としていました。
これらの結果、サービスを稼働させる観点において、アプリケーションサーバは完全に AWS 提供のサービス以外とは通信を行わないため、容易にインスタンスの追加や削除が出来るようになっています。
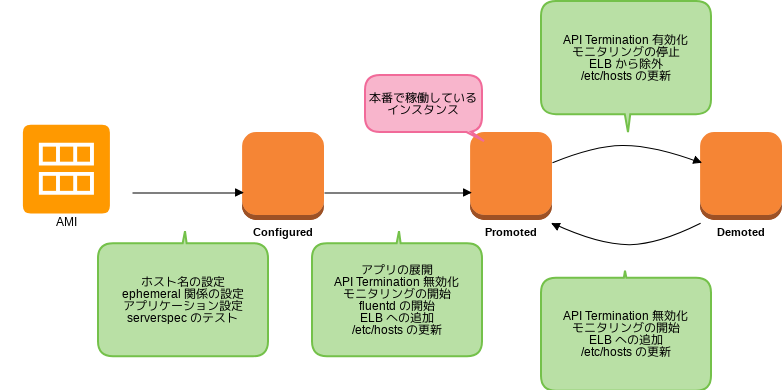
インスタンスの「状態」の導入
インスタンスには以下の三つの「状態」を持たせ、その値を EC2 のタグで管理しています。
- 構成が完了 ( Configured )
- 本番へ昇進 ( Promoted )
- 本番から降格 ( Demoted )
各々の状態変更時に実行されることは概ね以下の図のようになっています。
この「状態」を導入した主な理由はモニタリングすべきインスタンスを管理し、その継続性を保つためです。 インスタンスを入れ替えた前後で、当然ながらその影響がなかったかについてモニタリングしたいわけですが、例えば CloudWatch はインスタンス単位でのモニタリングですので途切れてしまいます。現在は傾向監視には munin を利用しており、インスタンスの入れ替え前後でも設定の変更が追随出来るよう、台数に増減がない場合は前後でホスト名を同じにするようにしています。ホスト名については EC2 のタグで管理しており、異なる「状態」でかつ同一のホスト名をもつインスタンスが存在できるよう、先述したホスト名の自動更新スクリプトではあわせてインスタンスの「状態」もチェックするようにしています。
アプリケーション設定の外部化
アプリケーション側では、Jenkins でビルドされた war をそのまま利用出来るよう、設定は完全にファイルとして外出しして、そのファイルをサーバ構成管理ツール側で管理するようにしました。これまで Maven などのビルドシステムが提供するプロファイルを利用して環境毎 ( ステージング、本番 ) のビルドをしていました。これは一見便利なのですが、例えば対応したい環境が増えるとどうしても個別ビルドする必要が出てきて Jenkins をトリガーとしたワークフローを複雑にしてしまいがちです。逆にどの環境でも同じ war を使えるようにしたことで、ステージング環境含め、 Git にタグを打った以降のリリースを自動化するワークフローを比較的シンプルに作ることが出来した。
些細なことに聞こえるかもしれませんが、アプリケーションのコードを書いていた経験からすると、アプリケーションの事はアプリケーション側で面倒みたくなるため、その設定がアプリケーションのリポジトリ外にあることに違和感は少なからずあります。ですので、こういったところは開発チームと運用まで見据えて一緒に設計していく事が肝のようにも思います。
その他
最後に日々の運用という観点でいうと、Packer や Vagrant は概ね想定通り AMI 作成後にインスタンスをターミネートしてくれるのですが、エラーが重なった場合、稀にゴミインスタンスが残ってしまう事がありました。ですので、日次でインスタンス数の増減をチェックし、想定外のインスタンス数に変化があった場合に Typetalk に通知するようにしています。まだツールが不安定な側面もある分、利用者側でのこういったチェックは欠かせないでしょう。
またログの管理は、従来は日次のローテート処理後に S3 にアップロードあげる運用をしていましたが、fluentd 経由で随時 S3 にログをあげるように変更しました。
後に知ったのですが、ここにあげた工夫点の多くは Twelve-Factor App で述べられている事と共通しています。抽象的な表現も多いですが、こちらはよく概念としてまとまっていますので、是非ご参照ください。
さて、
後編では実際の運用を通じて得た知見と今後の課題について紹介します。